文本分类三
1.TextCNN
(1)概述
- 利用CNN进行文本分类,和TextRNN仅仅在文本表示上有区别,对文本向量分类的操作是相同的。
- TextCNN比TextRNN的主要优势在于训练速度快
- TextCNN重点
- 将文本表示成词向量矩阵,称为文本词向量矩阵。
- 利用若干数目不同尺寸的卷积核,对文本词向量矩阵进行信息提取,然后经池化层得到有效信息。
- 将每一个卷积核提取到的有效信息拼接在一起得到文本的向量表示。
(2)网络结构
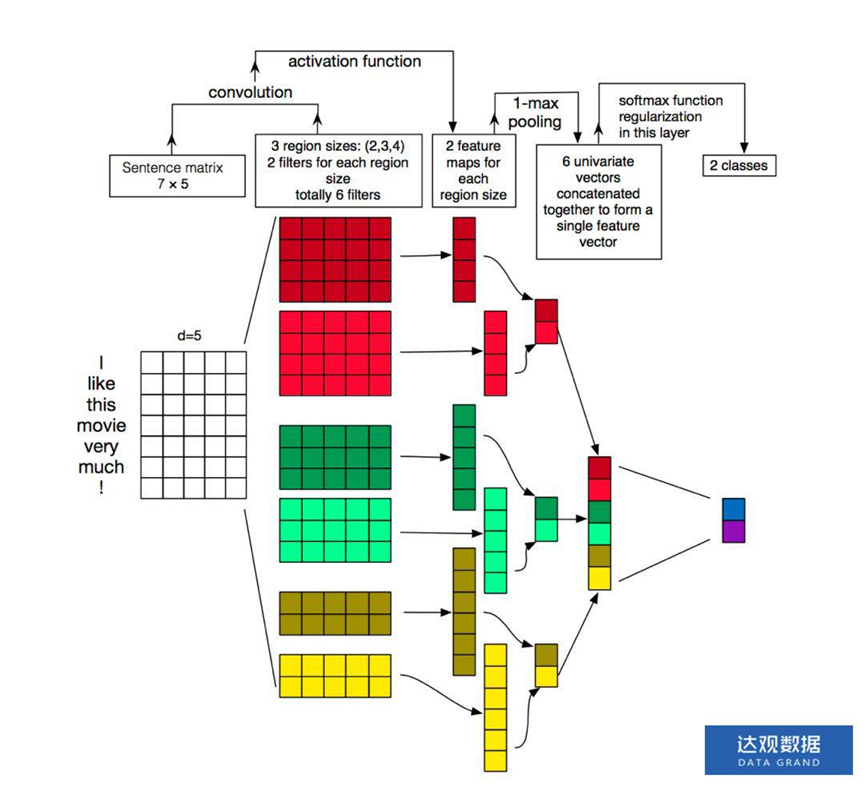
(3)结构解析
一共包含5层
-
词向量层
将文本表示成文本词向量矩阵。文本中的每个词,都将其映射到词向量空间,假设词向量为d维,则n 个词映射后,相当于生成一张n*d维的向量矩阵。
note:
实际项目中,每一个文本包含的单词数量不一定相同,若要批量处理,需要将所有文本填充至相同长度。
-
卷积层
使用多种尺寸的多个卷积核作用于词向量图,每个卷积核以一定步长在 词向量图上滑动,生成不同的feature map(一维向量),feature map向量的长度=$\frac{text_len-kernal_size}{stride}-1$
其中,text_len为文本的长度(单词数),kernal_size为卷积核的长度,stride为卷积核移动的步长。
note:
-
卷积核是一个二维的参数矩阵,矩阵的宽度要求和词向量的维度d相同,长度可以任意指定。一般会取多种尺寸的卷积核,如[2,d],[3,d],[4,d],这实际上提取的是文本的n_gram信息。
-
对于每一种尺寸的卷积核的数量都是可以任意指定的。
-
-
pooling层
每一个卷积核作用在文本词向量矩阵上都会生成一个feature map向量,pooling层就是对这个feature map向量的信息进一步的筛选。常用有k-maxpooling,mean-pooling两种池化方式。
-
k-maxpooling
k-maxpooling是取feature map向量中最大的k个点,构成一个长度为k的向量。
note:k的值可以指定,一般取1~3。
-
mean-pooling
k-maxpooling是对feature map向量上所有的点的值求平均,得到一个值。
-
-
连接层
一个卷积核作用在文本词向量矩阵上都会生成一个feature map向量,一个feature map向量经过池化层都会得到一个点或者一个较短的向量。最后直接将这些点或者向量串接起来就得到了文本的向量表示。
-
输出层(分类)
先接一个线性层将文本表示v映射到类别数目,再根据问题用softmax或者sigmoid输出各个类别的概率。
(4)网络搭建
class textCNN(nn.Module):
def __init__(self, args):
super(textCNN, self).__init__()
vocb_size = args['vocb_size']
dim = args['dim']
n_class = args['n_class']
max_len = args['max_len']
embedding_matrix=args['embedding_matrix']
ker_size = [3, 4, 5, 6]
in_channels = 256
out_channels = 80
self.topks = 1
self.embeding = nn.Embedding(vocb_size, dim, _weight=embedding_matrix)
self.dropout = nn.Dropout()
self.conv1 = nn.Sequential(
nn.Conv1d(in_channels=in_channels, out_channels=out_channels, kernel_size=ker_size[0], stride=1),
nn.BatchNorm1d(out_channels),
nn.ReLU(),
nn.MaxPool1d(kernel_size=max_len-ker_size[0]+1)
)
self.conv2 = nn.Sequential(
nn.Conv1d(in_channels=in_channels, out_channels=out_channels, kernel_size=ker_size[1], stride=1),
nn.BatchNorm1d(out_channels),
nn.ReLU(),
nn.MaxPool1d(kernel_size=max_len-ker_size[1]+1)
)
self.conv3 = nn.Sequential(
nn.Conv1d(in_channels=in_channels, out_channels=out_channels, kernel_size=ker_size[2], stride=1),
nn.BatchNorm1d(out_channels),
nn.ReLU(),
nn.MaxPool1d(kernel_size=max_len-ker_size[2]+1)
)
self.conv4 = nn.Sequential(
nn.Conv1d(in_channels=in_channels,
out_channels=out_channels, kernel_size=ker_size[3], stride=1),
nn.BatchNorm1d(out_channels),
nn.ReLU(),
nn.MaxPool1d(kernel_size=max_len-ker_size[3]+1),
)
self.out = nn.Sequential(
nn.Linear(out_channels*4*self.topks, n_class),
nn.Softmax()
)
def forward(self, x):
x = self.embeding(x) #[100, 64, 256]
x = self.dropout(x)
x = x.permute(0, 2, 1) #[100, 256, 64]
x1 = self.conv1(x) #[100, 80, maxlen-ker_size] --> [100, 80, 1]
x1 = x1.view(x1.size(0), -1)
x2 = self.conv2(x)
x2 = x2.view(x2.size(0), -1)
x3 = self.conv3(x)
x3 = x3.view(x3.size(0), -1)
x4 = self.conv4(x)
x4 = x4.view(x4.size(0), -1)
x = torch.cat((x1, x2, x3, x4), 1)
output = self.out(x)
return output
2.TextRCNN
-
先后利用RNN、CNN对文本进行信息提取。
-
TextCNN和TextCNN的区别仅仅在于上文提到的词向量层。
TextCNN在词向量层,是把文本表示成词向量矩阵,而TextCNN是把文本表示成词隐状态向量矩阵。即先将文本先输入RNN循环神经网络,得到每一个时刻(单词)对应的隐状态(输出),然后用单词的隐状态替代词向量,将文本表示成词隐状态向量矩阵。
3.DPCNN
Deep Pyramid Convolutional Neural Networks
本质是一种深层的cnn,能有效表达文本长距离关系的复杂度词粒度的CNN。
(1)网络结构
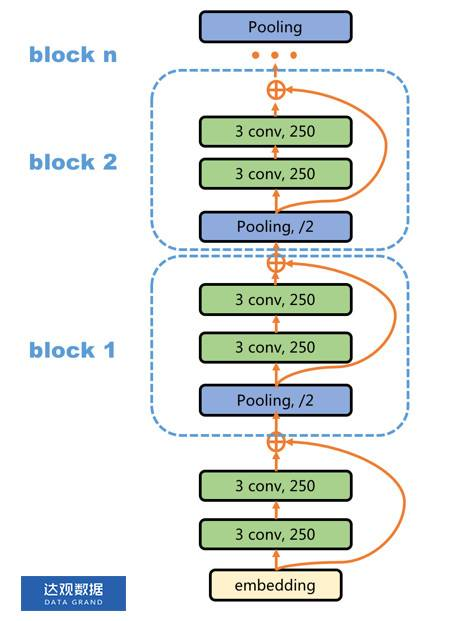
(2)结构解析
-
Region embedding
用channels_size个尺寸为[3,dim]的卷积核,对文本的词向量矩阵,以步长stride=1,进行卷积,生成channels_size个长度为sent_len-2的特征向量。将这channels_size个特征向量拼接在一起就可 以组成一个维度为[sent_len-2,channels_size]的矩阵,称 Region embedding。
-
等长卷积
-
先对Region embedding首尾填充一个长度为channels_size 的0向量。
-
取channels_size个尺寸为[3,dim]的卷积核,以步长stride=1,对Region embedding作卷积操作。
经 过一个卷积核能得到一个长度为sent_len-2的一维特征向量,由于选取了channel_size个卷积核,故一共能得到channel_size个一维向量,可以将它们拼接成一个维度为[sent_len-2,channels_size]的矩阵(维度同Region embedding)
-
举例
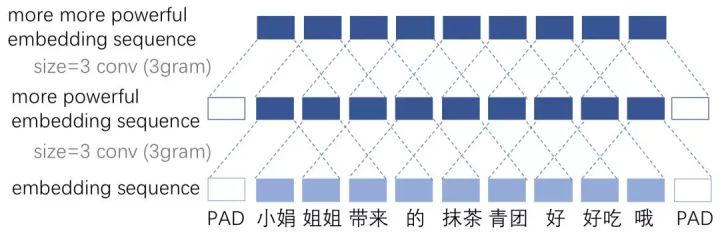
-
-
1/2池化层
-
池化前,对经过等长卷积得到的矩阵中的每一个特征向量的末端填充一个0。
-
取尺寸为[3,1]的池化窗口,步长为2,对每一个特征向量进行池化,每个特征向量就会生成一个长度减半的向量。然后把所有生成的向量拼接到一起,得到维度为[(sent_len-2)/2,channels_size]的矩阵。
-
举例
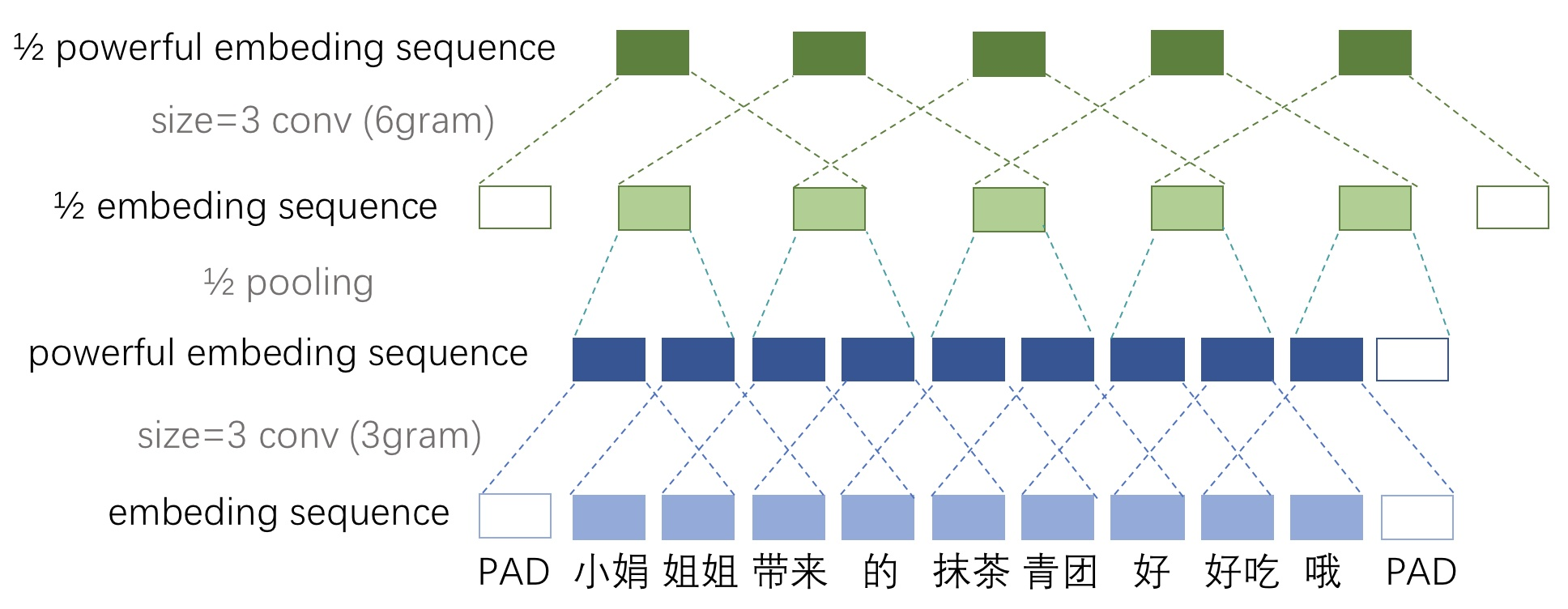
-
-
结构梗概
- ①对文本对应的词向量矩阵,先用3_gram的 卷积核做一次卷积得到Region embedding。
- ②对Region embedding先连续做两次等长卷积,再做一次1/2池化,使Region embedding在第一个维度上减半。
- ③重复②中操作,直至Region embedding的第一个维度的长度变为2。此时Region embedding的维度为[2,channels_size]
- ④把③中得到的Region embedding矩阵拉伸为一维,即维度变为[2*channels_size],作为文本的向量表示。
-
补充:
如(1)中的网络结构所示,网络中每个BLOCK用到了残差连接的Trick,对与层次比较深的复杂网络,使用残差连接能在一定程度上缓解梯度消失问题,并加速模型的收敛。
(3)网络搭建
class DPCNN_model(nn.Module):
def __init__(self, args):
super(DPCNN_model, self).__init__()
vocb_size = args['vocb_size']
dim = args['dim']
n_class = args['n_class']
# max_len = args['max_len']
embedding_matrix = args['embedding_matrix']
self.embeding = nn.Embedding(vocb_size, dim, _weight=embedding_matrix)
self.channel_size = 200
self.conv_region_embedding = nn.Conv2d(1, self.channel_size, (3, dim), stride=1) #[N, max_length, dim]
self.BatchNorm = nn.BatchNorm2d(self.channel_size)
self.conv3 = nn.Conv2d(self.channel_size, self.channel_size, (3, 1), stride=1)
self.pooling = nn.MaxPool2d(kernel_size=(3, 1), stride=2)
self.padding_conv = nn.ZeroPad2d((0, 0, 1, 1)) #上下填充
self.padding_pool = nn.ZeroPad2d((0, 0, 0, 1)) #仅下方填充
self.act_fun = nn.ReLU()
self.linear_out = nn.Linear(2 * self.channel_size, n_class)
self.softmax = nn.Softmax()
def forward(self, x):
batch = x.shape[0]
x = self.embeding(x) # [100,64,256]
x = torch.unsqueeze(x, 1) # [100,1,64,256] 二维卷积,输入维度为4
# Region embedding
x = self.conv_region_embedding(x)
# [batch_size, channel_size, length=句长-2, 1]
x = self.BatchNorm(x)
x = self.act_fun(x)
px = x
# 连续两次等长卷积
x = self.padding_conv(x) # pad保证等长卷积,先通过激活函数再卷积
x = self.conv3(x)
x = self.BatchNorm(x)
x = self.act_fun(x)
x = self.padding_conv(x)
x = self.conv3(x)
x = self.BatchNorm(x)
x = self.act_fun(x)
x = x + px #残差连接
while x.size()[-2] > 2:
# 直到length==2, 长度设置时候有要求,最好是2的n次方
x = self._block(x)
x = x.view(batch, 2 * self.channel_size)
x = self.linear_out(x)
x = self.softmax(x)
return x
def _block(self, x):
x = self.padding_pool(x)
px = self.pooling(x)
x = self.padding_conv(px)
x = self.conv3(x)
x = self.BatchNorm(x)
x = F.relu(x)
x = self.padding_conv(x)
x = self.conv3(x)
x = self.BatchNorm(x)
x = F.relu(x)
# Short Cut
x = x + px
return x
参考链接:
https://ai.tencent.com/ailab/media/publications/ACL3-Brady.pdf
