Bert融入知识——学习笔记
本文主要介绍两篇都叫ERNIE的论文,两者都通过融入知识对Bert模型进行改进。本文主要关注两论文对应模型是如何融入知识的、以及模型的预训练任务。
1. Enhanced Language Representation with Informative Entities
1.1 原文
https://www.aclweb.org/anthology/P19-1139.pdf (由清华和华为共同完成)
1.2 摘要
在大规模语料库上预先训练的BERT等神经语言表示模型可以很好地从纯文本中捕获丰富的语义模式,并通过微调的方式一致地提高各种NLP任务的性能。然而,现有的预训练语言模型很少考虑融入知识图谱(KGs),知识图谱可以为语言理解提供丰富的结构化知识。我们认为知识图谱中的信息实体可以通过外部知识增强语言表示。在这篇论文中,我们利用大规模的文本语料库和知识图谱来训练一个增强的语言表示模型(ERNIE),它可以同时充分利用词汇、句法和知识信息。实验结果表明,ERNIE在各种知识驱动任务上都取得了显著的进步,同时在其他常见的NLP任务上,ERNIE也能与现有的BERT模型相媲美。本文的源代码和实验细节可以从 https://github.com/thunlp/ERNIE 获得。
1.3 两大挑战及解决方法:
(1) 将外部知识融入语言表示模型将面临两大挑战。(这是论文里说的)
-
Structured Knowledge Encoding ( 结构化知识编码 )
对于给定的文本,如何高效地抽取并编码对应的知识图谱中的信息;
-
Heterogeneous Information Fusion( 异构信息融合 )
语言表示的预训练过程和知识表示过程有很大的不同,它们会产生两个独立的向量空间。因此,如何设计一个特殊的预训练目标,以融合词汇、句法和知识信息又是另外一个难题。
(2)为此,本文提出了ERNIE模型,同时在大规模语料库和知识图谱上预训练语言模型:
- 抽取、编码知识信息
首先识别文本中的实体,并将这些实体与知识图谱中相应的实体对齐。具体做法:采用知识嵌入算法(如TransE) 对KGs的图结构进行编码 ,并将得到的信息实体embedding作为ERNIE模型的输入。基于文本和知识图谱的对齐,ERNIE 将知识模块的实体表征整合到语义模块的底层。
-
语言模型的预训练任务
在训练语言模型时, 除了采用Bert中的遮蔽语言模型(MLM)和下一个句子预测(NSP)作为预训练的目标,为了更好地融合文本和知识特征,还设计了一个新的预训练目标——dEA:在输入文本中随机屏蔽一些实体,要求模型从KGs中选出适当的实体来完成对齐。
1.4 模型结构
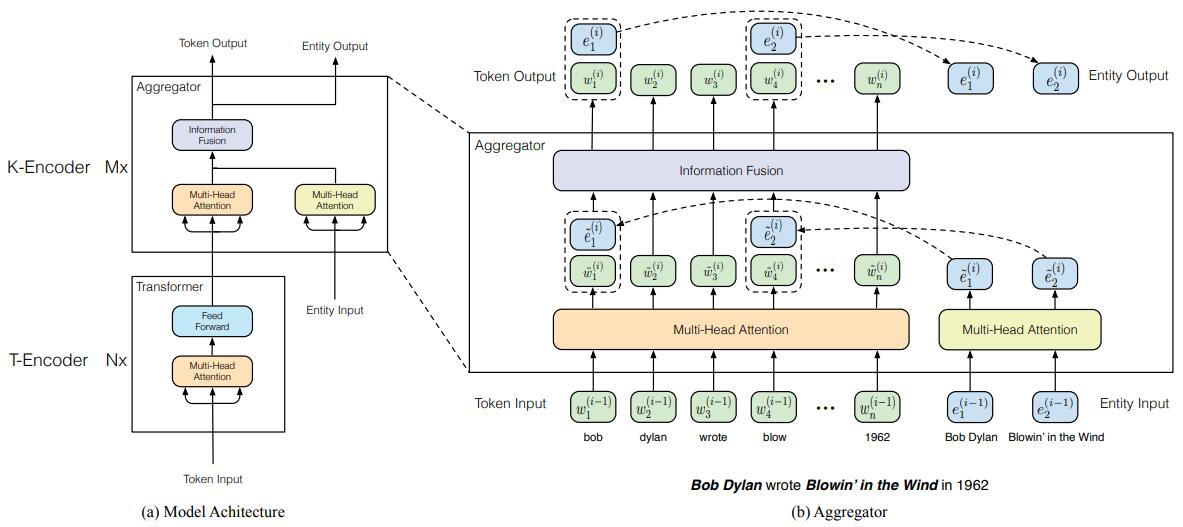
模型结构主要包含两个层叠的模块,T-Encoder 和 K-Encoder。
-
T-Encoder(textual encoder)
结构同Bert,包含Nx层,每一层包含两个子层:一个Muti-Head Attention子层、一个Feed Forward子层。
T-Encoder的输入为文本对应的 tokens序列,输出为与文本中各个token对应的隐状态序列,用于捕获输入文本中的词法和语法信息。
-
K-Encoder( knowledgeable encoder )
K-Encoder是模型体现融入知识的主要结构,包含Mx层,每一层包含三个子层:
-
一个以T-Encoder的输出(Token Input)为输入的Muti-Head Attention子层,
-
一个以实体Embedding序列(Entity input:通过TranE等方法得到)为输入的Muti-Head Attention子层,
-
一个融合文本信息和实体信息的Information Fusion层,输出为Token Output,Entity Output分别与Token Input、Entity input维度相同。
-
模型对应计算过程:
设文本对应token序列为 {w1, . . . , wn} , entity 序列为 {e1, . . . , em} 。
-
{w1, . . . , wn} = T-Encoder({w1, . . . , wn})
token序列{w1, . . . , wn}先经过T-Encoder层,同Bert(一个多层双向 Transformer encoder 结构),在输入时,对每个token的 token embedding, segment embedding, positional embedding 相加作为input embedding,输出的{w1, . . . , wn} 为与文本每个token相对应的隐状态序列。
-
{e1, . . . , em} = TransE ({e1, . . . , em})
entity 序列 {e1, . . . , em} 先通过一个知识嵌入模型(如 TransE),变成一个entity embedding 序列 {e1, . . . , em} 。
- {w1, . . . , wn}, {e1, . . . , en} = K-Encoder( {w1, . . . , wn}, {e1, . . . , em}).
K-Encoder以T-Encoder的输出 {w1, . . . , wn}、通过 TransE得到的 {e1, . . . , em} 为输入,输出仍为和输入同维度的 {w1, . . . , wn}和{e1, . . . , en}。
K-Encoder的具体计算如下:(K-Encoder是一个多层的结构,每一层均为一个称作aggregator的结构)
-
每一层的aggregator以前一层的aggregator的输出$\left{\boldsymbol{w}{1}^{(i-1)}, \ldots, \boldsymbol{w}{n}^{(i-1)}\right}$、$\left{e_{1}^{(i-1)}, \ldots, e_{m}^{(i-1)}\right}$作为输入,分别经过两个不同的multi-head self-attentions层。 \(\begin{aligned}\left\{\tilde{\boldsymbol{w}}_{1}^{(i)}, \ldots, \tilde{\boldsymbol{w}}_{n}^{(i)}\right\} &=\mathrm{MH}-\mathrm{ATT}\left(\left\{\boldsymbol{w}_{1}^{(i-1)}, \ldots, \boldsymbol{w}_{n}^{(i-1)}\right\}\right) \\\left\{\tilde{\boldsymbol{e}}_{1}^{(i)}, \ldots, \tilde{\boldsymbol{e}}_{m}^{(i)}\right\} &=\mathrm{MH}-\mathrm{ATT}\left(\left\{\boldsymbol{e}_{1}^{(i-1)}, \ldots, \boldsymbol{e}_{m}^{(i-1)}\right\}\right) \end{aligned}\)
-
然后,通过information fusion layer层对token序列和entity序列进行融合(即通过该层得到新的token和enitity的embedding,只不过新的embedding由原始的两部分embedding计算得到)
-
对于每一个token $w_j$,如果能找到与之对应的entity $e_k$,则对$w_j$和$e_k$ 的计算如下:Note:一个entity往往不止一个token,论文中只将entity和它的第一个token 对齐,非entity的首token当做第2种情况!!! \(\begin{aligned} \boldsymbol{h}_{j} &=\sigma\left(\tilde{\boldsymbol{W}}_{t}^{(i)} \tilde{\boldsymbol{w}}_{j}^{(i)}+\tilde{\boldsymbol{W}}_{e}^{(i)} \tilde{\boldsymbol{e}}_{k}^{(i)}+\tilde{\boldsymbol{b}}^{(i)}\right) \\ \boldsymbol{w}_{j}^{(i)} &=\sigma\left(\boldsymbol{W}_{t}^{(i)} \boldsymbol{h}_{j}+\boldsymbol{b}_{t}^{(i)}\right) \\ \boldsymbol{e}_{k}^{(i)} &=\sigma\left(\boldsymbol{W}_{e}^{(i)} \boldsymbol{h}_{j}+\boldsymbol{b}_{e}^{(i)}\right) \end{aligned}\)
-
对于每一个token $w_j$,如果不能找到与之对应的entity $e_k$,则对$w_j$计算如下: \(\begin{aligned} \boldsymbol{h}_{j} &=\sigma\left(\tilde{\boldsymbol{W}}_{t}^{(i)} \tilde{\boldsymbol{w}}_{j}^{(i)}+\tilde{\boldsymbol{b}}^{(i)}\right) \\ \boldsymbol{w}_{j}^{(i)} &=\sigma\left(\boldsymbol{W}_{t}^{(i)} \boldsymbol{h}_{j}+\boldsymbol{b}_{t}^{(i)}\right) \end{aligned}\)
-
最顶层 aggregator输出的token和enitity的表示序列作为 K-Encoder 的输出。
1.5 融入知识的预训练
为了通过实体信息融入知识,论文提出了一个新的预训练任务 denoising entity auto-encoder (dEA)。
dEA:
-
任务:随机遮蔽一些token对应的entity,让模型对token对应的entity进行预测。
Note:论文并不是让模型从知识图谱中所有的实体中找出token对应的实体,而是从token序列对应的实体序列中$\left{e_{1}, \ldots, e_{m}\right}$中找。即: \(p\left(e_{j} | w_{i}\right)=\frac{\exp \left(1 \text { inear }\left(\boldsymbol{w}_{i}^{o}\right) \cdot \boldsymbol{e}_{j}\right)}{\sum_{k=1}^{m} \exp \left(1 \text { inear }\left(\boldsymbol{w}_{i}^{o}\right) \cdot \boldsymbol{e}_{k}\right)}\) 论文中并没有提到遮蔽的比例。
预训练模型的Loss为 dEA, MLM and NSP三部分loss的和。
1.6 微调
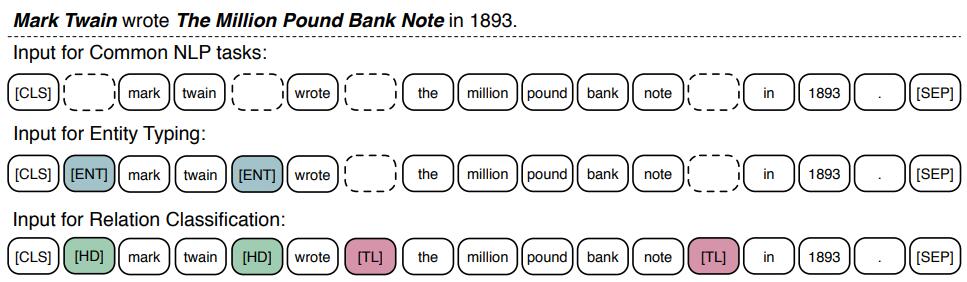
类似与Bert,ERNIE模型通过引入一些特殊的token,使预训练模型更好的应用于下游任务。尤其针对知识驱动的任务,引入了特殊的token
-
[CLS]
对于一般的NLP任务,可以将句子首部的[CLS]在最后一层的表示作为句子的表示。
-
[HD]和[TL]
针对关系分类的任务,分别在 head entitie 和 tail entities实体的两侧加上 [HD]和 [TL]标记。最后仍然使用[CLS]的表示进行分类,这里的 [HD]和 [TL]标记可以看作突出强调的作用。
- [ENT]
针对实体分类任务,在实体两侧加上[ENT] 标记,最后也仍使用[CLS]的表示进行分类。
1.7 其他:
为了减少预处理部分,实体识别不准确的影响,论文使用了如下trick。
对于每一个 token-entity alignment :
- 5%情况下,随机替换某token对应的entity。目的:预处理得到的token-entity alignment并不一定都是正确的,即某些抽取得到的实体实际上可能并不是实体,通过随机替换来减少错误的对齐信息带来的影响。
- 15%情况下,遮蔽整个 token-entity alignment信息,目的:预处理得到的token-entity alignment并不一定是完备的,有些实体可能没被抽取出来,通过此方式来减少此类问题带来的影响。
- 80%情况下,保持token-entity alignment不变。
2. Enhanced Representation through Knowledge Integration
1.1 原文
https://arxiv.org/pdf/1904.09223.pdf (百度ERNIE 1.0)
1.2 摘要
我们提出了一个新的知识增强的语言表示模型—— ERNIE (Enhanced Representation through kNowledge IntEgration) 。受Bert遮蔽策略的启发, ERNIE通过知识遮蔽策略增强语言表示,包括实体级 entity-level遮蔽和 phrase-level 遮蔽。 Entity-level 的策略遮蔽实体(一个实体通常由多个词组成), Phrase-level 的策略遮蔽整个短语(一个短语通常由多个词组成,构成一个概念单元)。 实验结果表明,ERNIE在自然语言推理、语义相似度、命名实体识别、情感分析和问答等5项中文自然语言处理任务中均取得了SOTA的效果。我们还证明了ERNIE在完形填空测试中具有更强的知识推理能力。
1.3 贡献(论文里说的)
- 提出了一种新的语言模型学习方法,该方法遮蔽了短语和实体,从而隐式地学习这些单位的句法和语义信息。
- ERNIE在各种中文自然语言处理任务上取得SOTA效果。
- 开源了ERNIE的代码和预训练模型。
说白了,百度ERNIE1.0主要是对Bert的MLM任务进行了改进,Bert是随机遮蔽一些token,而ERNIE遮蔽的是完整的实体或短语,在这些短语和实体是一种先验的知识,可以是其他方法抽取出来的。
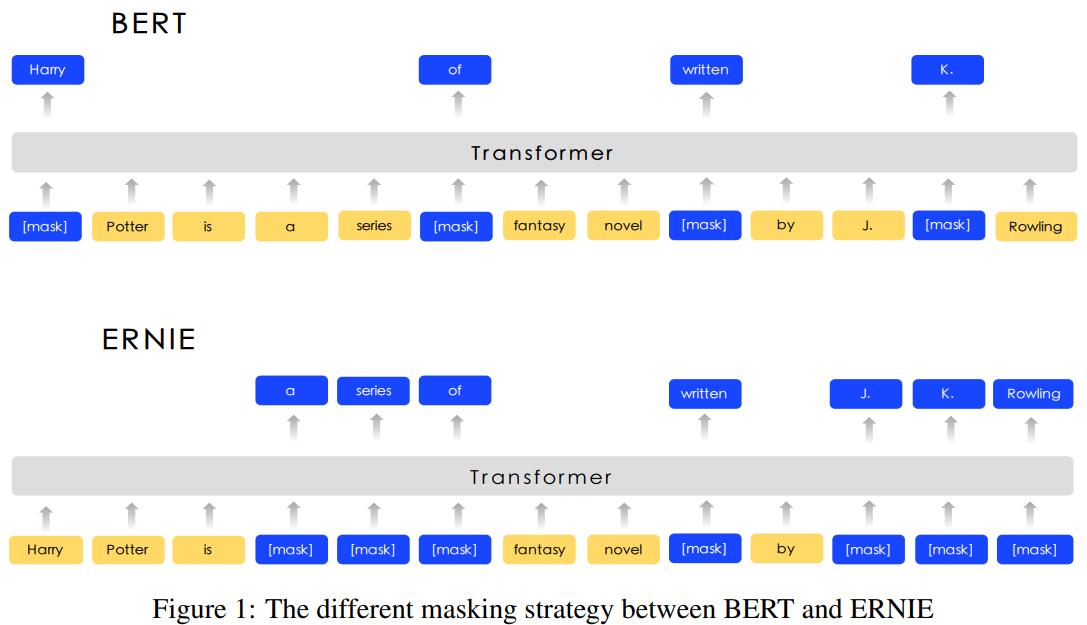
1.4 模型
- Transformer Encoder
同Bert, ERNIE 使用了多层的 Transformer Encoder 结构学习上下文的表示。同样,增加了[CLS]标记,每一个token的输入表示为token, segment and position embeddings的和。
- Knowledge Integration (使用先验知识改进的MLM)
使用先验知识增强预训练的语言模型——提出了一种多阶段的知识掩蔽策略,将短语级别和实体级别的知识融入语言表示中,而不是直接增加知识的嵌入。(仍保留了Bert的遮蔽方式)
- Basic-Level Masking
同Bert的方式,以15%的概率随机遮蔽英文的单词或者中文的字。通过这种方式,高层的语义信息很难被建模。
-
Phrase-Level Masking
短语是作为一个概念单元的一组单词或字符。 对于英语,使用词汇分析和分块工具来获取句子中短语的边界,并使用一些语言相关的分割工具来获取其他语言(如汉语)中的单词/短语信息。在短语级遮蔽阶段,随机遮蔽句子中的短语,预测被遮蔽的短语中的所有token。 在这个阶段,短语信息将被编码到词嵌入中。
-
Entity-Level Masking
通常实体在句子中包含重要信息。与短语级别的遮蔽一样,首先分析句子中的命名实体,然后随机遮蔽句子中的实体,预测被遮蔽的实体中的所有token。
-
DLM
因为相同回复的不同问题往往是相似的,所以对话数据对于语义表示很重要。ERNIE还提出了Dialogue Language Model对Query-Response的对话结构建模。 类似Bert对句子对建模,并用Segment Embedding区分不同的句子,ERNIE对多轮对话(其实就3句话 :QRQ或 QRR或 QQR, Q表示询问,R表示回复) 进行建模,并用 Dialogue Embedding 进行区分。如下所示:
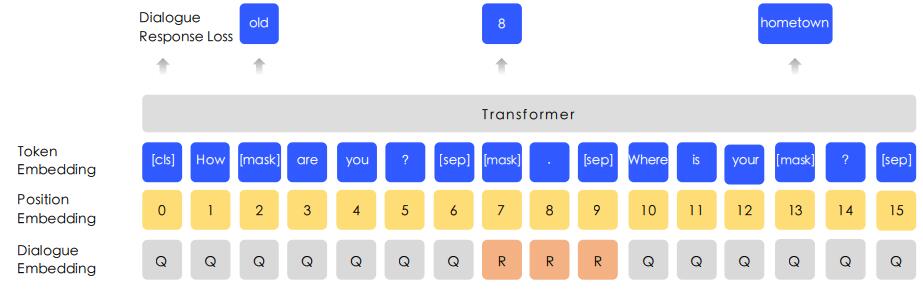
DLM的任务是对话的真假进行预测:
- 用一个句子随机替换对话中的query或 response,然后让模型判断对话的真假(即判断对话中句子是否被替换过)。
DLM任务帮助ERNIE学习对话中的隐含关系,增强了模型学习语义表示的能力。
3. 总结
- 清华的ERNIE通过输入由TransE方法得到的实体Embedding的方式来融入知识图谱的信息;并比Bert新增加了一个实体预测的任务来进一步融入实体的知识。
- 百度的ERNIE使用先验的命名实体和短语知识改进了Bert的MLM的mask策略,进行短语和实体级别的mask和predict,以隐含地融入实体、句法的知识;并使用对话场景的DLM任务替换了Bert的NSP任务,学习语义表示。
