Learning Bert
BERT—— Bidirectional Encoder Representations from Transformers
1.Bert模型
(1) BERT原文:
Pre-training of Deep Bidirectional Transformers for Language
(2) 模型outline
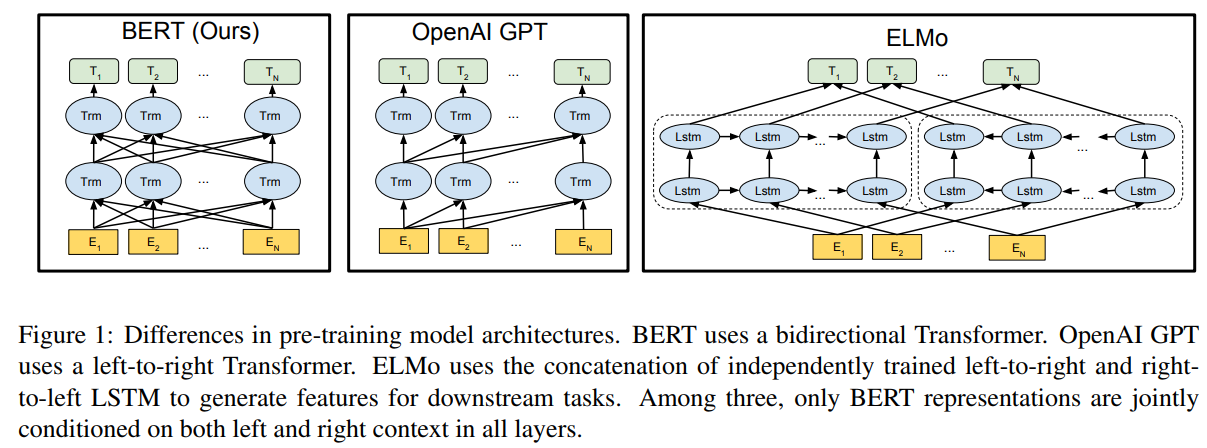
Bert结构略述:
-
Bert的结构参考了Transformer的encoder部分、是一种双向语言模型(encoder不会遮住后面的词) 。
-
Note:
$GPT$模型参考的是Transformer的decoder部分、是一种单向语言模型(decoder会遮住后面的词) 。$ELMO$模型是使用双向LSTM进行特征提取、是一种不完全的双向语言模型(仅在最后将两个方向的特征拼接起来,中间过程中,每一个词位上的特征还是仅仅依赖于一个方向)
(3) 两种Bert模型(论文里介绍的)
① Bert-base: L=12, H=768, A=12, Total Parameters=110M
② Bert-large: L=24, H=1024, A=16, Total Parameters=340M
其中,L表层数、H为隐藏层维度、A为自注意力头的数量。
(4) Bert的应用
Bert一般通过fine-tuning 的方式应用到下游任务。
Note:GPT也是通过fine-tuning 的方式应用到下游任务,而ELMO是以Feature-based方式。
(5) Bert的输入表示(Embeddings)
Bert的在预训练时的输入时一个句子对(当然,应用到下游任务时可以是单个句子)。句子在输入前需要先tokenize(将文本变成token的序列,token可以是词、标点符号等),bert处理英文时会做 WordPiece (将复合词拆成几部分),bert处理中文时,并不会分词,而是基于字的。
Bert会在句子对最前面添加一个token([CLS]),可将这个token在模型的最后一层的隐状态作为句子对的表示应用到下游任务。并且,Bert会在两个句子之间添加一个token([SEP])进行隔开,两个句子也分别对应不同Segment Embedding以示区分。(Note:虽然这里说将最后一层的隐状态作为表示,但实际上也可以将不同层的隐状态拼接起来作为表示,等等)
Bert 的输入表示( input embeddings )由每一个token对应的Token Embedding、Segment Embedding、Position Embedding相加构成。
如下图所示:
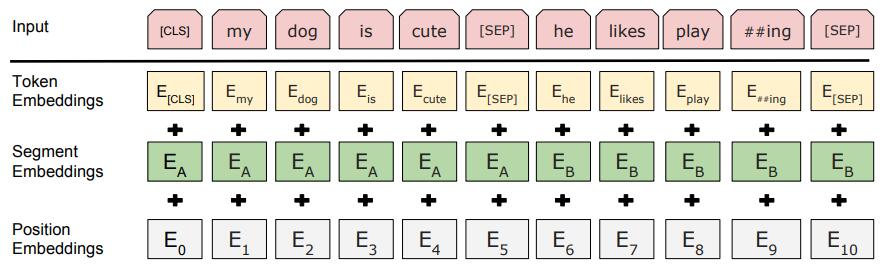
Note:Segment Embedding、Position Embedding和Token Embedding都是需要学习的参数,这里的Position Embedding不同于Transfomer原文中Position Embedding用公式直接计算得到。
(6) Bert模型的两个预训练任务
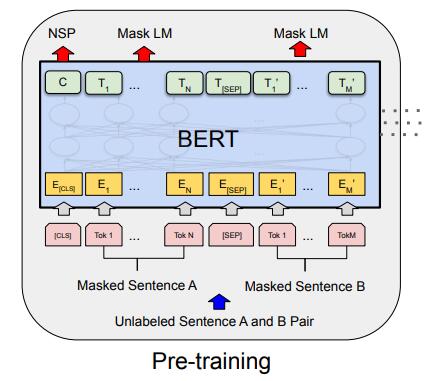
-
Masked Language Model(MLM:类似完形填空问题)
概述: 随机遮蔽(mask)掉句子中的一些token,然后利用上下文对遮蔽的token进行预测。这个任务主要是学习每个token的上下文表示。
怎么mask:随机对句子中15%的token 进行mask,并且对于被mask的token也并非直接替换成[MASK]标记,而是:
- 80%情况下,被mask掉的token会直接被[MASK]标签代替;
- 10%的情况下,被mask掉的token会用一个随机的token替换掉;
- 10%的情况下,被mask掉的token不变。
注意:被选中mask的那15%的词都会被预测,而不仅仅是被替换为[MASK]标签的词。
Note:为什么对于被mask的token不直接替换成[MASK]标记?答:①10%的情况用一个随机的token替换,是为了增加噪声,增加模型的稳定性和泛化能力??? ②10%的情况下被mask掉的token不变,是减轻[MASK这个token在微调期间不会出现而引起的不对称带来的影响 ,使得最终的表示偏向于实际的词。真的可以吗 ???
mask相关源码如下:
# mask策略 def _apply_mask(docs, random_words, mask_prob=0.15): # This needs to be here to avoid circular imports from .tokens.doc import Doc N = sum(len(doc) for doc in docs) mask = numpy.random.uniform(0.0, 1.0, (N,)) mask = mask >= mask_prob # false对应的token会做mask处理 i = 0 masked_docs = [] for doc in docs: words = [] for token in doc: if not mask[i]: word = _replace_word(token.text, random_words) else: word = token.text words.append(word) i += 1 spaces = [bool(w.whitespace_) for w in doc] masked_docs.append(Doc(doc.vocab, words=words, spaces=spaces)) return mask, masked_docs # mask:标记哪些token被mask, masked_docs为mask后文本 # 对应该被mask的token的处理 def _replace_word(word, random_words, mask="[MASK]"): roll = numpy.random.random() if roll < 0.8: return mask elif roll < 0.9: return random_words.next() else: return word怎么预测mask:用标记为[MASK] 的toekn的最后一层的隐状态,映射到词表维度,然后softmax即可。
(实际的代码会将所有token在最后一层的隐状态先过一个带gelu激活函数的同为hidden_size的线性层,并做LayerNorm,然后才会将[MASK]映射到词表长度作分类)
相关源码如下:
# 对所有toekn在最后一层的隐状态再做变换 class BertPredictionHeadTransform(nn.Module): def __init__(self, config): super(BertPredictionHeadTransform, self).__init__() self.dense = nn.Linear(config.hidden_size, config.hidden_size) if isinstance(config.hidden_act, str) or (sys.version_info[0] == 2 and isinstance(config.hidden_act, unicode)): self.transform_act_fn = ACT2FN[config.hidden_act] else: self.transform_act_fn = config.hidden_act self.LayerNorm = BertLayerNorm(config.hidden_size, eps=config.layer_norm_eps) def forward(self, hidden_states): hidden_states = self.dense(hidden_states) hidden_states = self.transform_act_fn(hidden_states) hidden_states = self.LayerNorm(hidden_states) return hidden_states # 预测MASK class BertLMPredictionHead(nn.Module): def __init__(self, config): super(BertLMPredictionHead, self).__init__() self.transform = BertPredictionHeadTransform(config) # The output weights are the same as the input embeddings, but there is an output-only bias for each token. self.decoder = nn.Linear(config.hidden_size,config.vocab_size, bias=False) self.bias = nn.Parameter(torch.zeros(config.vocab_size)) def forward(self, hidden_states): hidden_states = self.transform(hidden_states) hidden_states = self.decoder(hidden_states) + self.bias return hidden_states疑问:
- 因为Bert对英文进行WordPiece,对中文基于字tokenize,被Mask的token可能不是一个完整的词,而是一个词的一部分。这种做法好还是Mask完整的词好?
- Bert是对15%的token 进行mask,如果对一个句子中所有的词分开mask(即mask一个词产生一个样本)效果会更好吗?
-
Next Sentence Prediction (NSP: 下一句预测 )
概述: 输入句子A和B,预测B是否为A的下一个句子 。这个任务能学习句子级别的表示和判断句子关系的能力,使模型适应 问答(QA)和自然语言推理(NLI) 等任务。
怎么选的句子: 选定两个句子 A, B 作为预训练样本,B 有 50% 的可能为A的下一句, 有 50% 的可能是语料库中的随机句子 。
怎么预测是否为下一个句子:用句子对的第一个token,即[CLS]在最后一层的隐状态作为语句对的表示,再做二分类的预测。(实际的代码会将[CLS]在最后一层的隐状态先过一个带Tanh激活函数的同为hidden_size的线性层,在映射到长度为2的向量作分类)
相关源码如下:
# 句子表示 class BertPooler(nn.Module): def __init__(self, config): super(BertPooler, self).__init__() self.dense = nn.Linear(config.hidden_size, config.hidden_size) self.activation = nn.Tanh() def forward(self, hidden_states): # We "pool" the model by simply taking the hidden state corresponding # to the first token. first_token_tensor = hidden_states[:, 0] pooled_output = self.dense(first_token_tensor) pooled_output = self.activation(pooled_output) return pooled_output # 句子关系预测 class BertOnlyNSPHead(nn.Module): def __init__(self, config): super(BertOnlyNSPHead, self).__init__() self.seq_relationship = nn.Linear(config.hidden_size, 2) def forward(self, pooled_output): seq_relationship_score = self.seq_relationship(pooled_output) return seq_relationship_score
2.Bert预训练模型简介
谷歌开放了预训练的 BERT-Base 和 BERT-Large 模型,且每一种模型都有 Uncased 和 Cased 两种版本。 其中, Uncased版 在分词之前都转换为小写格式,并剔除所有 Accent Marker,而 Cased 会保留它们。因此,使用谷歌提供的Uncased版的预训练模型时,需要在预处理时对任务的语料做小写转换。作者表示一般使用 Uncased 模型就可以了,除非大小写对于任务很重要才会使用 Cased 版本。
预训练文件包含了三部分,即保存预训练模型权重的model文件、将 WordPiece 映射到单词 id 的 vocab 文件,以及指定模型超参数的 config 文件。
TensorFlow 版Bert 代码和预训练模型:https://github.com/google-research/bert
Pytorch版Bert 代码和预训练模型: https://github.com/huggingface/transformers
3. Huggingface transformers 教程(Pytorch调用Bert等预训练模型)
huggingface实现了Pytorch版本的GPT、Bert、XLNet、RoBERTa等模型,并提供了不同版本的预训练权重。
huggingface官方教程:https://huggingface.co/transformers/index.html
下面主要介绍Bert预训练模型加载和使用。
1. 首先安装 PyTorch Transformers
pip install transformers
2. 实际任务中,主要会用到一下三个类
-
transformers.BertConfig
Bert配置类,存储着Bert模型的各种超参数。后面BertModel实例化或者加载预训练模型时会使用。
-
transformers. BertTokenizer
Bert Tokenizer类,能够按照词表将文本划分成token序列, 并将各个token转换成id值。
该类所提供的方法参考如下代码:
from transformers import BertTokenizer tokenizer = BertTokenizer.from_pretrained('bert-base-uncased') text = "[CLS] Who was Jim Henson ? [SEP] Jim Henson was a puppeteer [SEP]" # tokenize:将文本字符串转换成token的序列 tokenized_text = tokenizer.tokenize(text) assert tokenized_text == ['[CLS]', 'who', 'was', 'jim', 'henson', '?', '[SEP]', 'jim', '[MASK]', 'was', 'a', 'puppet', '##eer', '[SEP]'] # convert_tokens_to_ids:将token序列转换成id序列 indexed_tokens = tokenizer.convert_tokens_to_ids(tokenized_text) # encode == tokenize + convert_tokens_to_ids INDEX_TOKENS = tokenizer.encode(text) # convert_ids_to_tokens: 将id序列转换成token序列 tokenized_text_ = tokenizer.convert_ids_to_tokens(indexed_tokens) # convert_tokens_to_string: 将token的序列转换成文本字符串 text_ = tokenizer.convert_ids_to_tokens(tokenized_text_) # decode == convert_ids_to_tokens + convert_tokens_to_string TEXT = tokenizer.decode(indexed_tokens) -
transformers.BertModel
(1)Bert模型类,就是Bert模型的主体,接收tokenize后并转换成id值的文本序列,输出各个token、句子的表示等。
(2)BertModel类 forward()方法部分代码如下所示:
def forward(self, input_ids, attention_mask=None, token_type_ids=None, position_ids=None, head_mask=None): ... embedding_output = self.embeddings(input_ids, position_ids=position_ids, token_type_ids=token_type_ids) encoder_outputs = self.encoder(embedding_output, extended_attention_mask, head_mask=head_mask) sequence_output = encoder_outputs[0] pooled_output = self.pooler(sequence_output) outputs = (sequence_output, pooled_output,) + encoder_outputs[1:] # add hidden_states and attentions if they are here return outputs # sequence_output, pooled_output, (hidden_states), (attentions)-
输入
-
input_ids:文本对应的id序列, shape = (batch_size, seq_len)
-
attention_mask :文本对应的pad标记序列, shape = (batch_size, seq_len), 1表示该位置未被填充,0表填充。
-
token_type_ids:用于区分文本中两个句子的的标记序列, shape = (batch_size, seq_len) 。 0表示相应token属于第一个句子, 1表示相应token属于第二个句子。
note:实际代码中为了batch训练,input_ids、token_type_ids都会用0来pad的。
-
输出
-
outputs:包含多个元素的元组
outputs第一个元素sequence_output为最后一层每个token的隐状态(batch_size, seq_len, hidden_size),
outputs第二个元素pooled_output 为整个文本的表示(batch_size, hidden_size)
(3)BertModel使用示例:
import torch from transformers import BertTokenizer, BertModel tokenizer = BertTokenizer.from_pretrained('bert-base-uncased') model = BertModel.from_pretrained('bert-base-uncased') input_ids = torch.tensor(tokenizer.encode("Hello, my dog is cute")).unsqueeze(0) # input_ids:(batch_size, seq_len) outputs = model(input_ids) sequence_output = outputs[0] # The last hidden-state of all tokens (batch_size, seq_len, hidden_size) pooled_output = outputs[1] # sentences represent (batch_size, hidden_size) -
3.三个类分别对应前面提到的预训练文件的三部分:
config 文件、vocab文件、model文件。并且这三个类都有 from_pretrained() 方法,用于加载相应的预训练文件。
-
from_pretrained() 方法
def from_pretrained(cls, pretrained_model_name_or_path, *model_args, **kwargs)pretrained_model_name_or_path:
该参数值可以是预训练文件的名字,或者预训练文件所在文件夹,或者预训练文件所在路径。
-
(1)当其为预训练模型的名字
只能是以下key值之一,若能匹配到key值,则会先到缓存目录中查看是否已经下载下来,若未下载下来,则系统转到value对应网址下载相应预训练文件到缓存目录中。若找不到对应key,则判断该参数是否为文件夹或者文件路径。
BERT_PRETRAINED_MODEL_ARCHIVE_MAP = { 'bert-base-uncased': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-uncased-pytorch_model.bin", 'bert-large-uncased': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-large-uncased-pytorch_model.bin", 'bert-base-cased': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-cased-pytorch_model.bin", 'bert-large-cased': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-large-cased-pytorch_model.bin", 'bert-base-multilingual-uncased': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-multilingual-uncased-pytorch_model.bin", 'bert-base-multilingual-cased': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-multilingual-cased-pytorch_model.bin", 'bert-base-chinese': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-chinese-pytorch_model.bin", 'bert-base-german-cased': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-german-cased-pytorch_model.bin", 'bert-large-uncased-whole-word-masking': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-large-uncased-whole-word-masking-pytorch_model.bin", 'bert-large-cased-whole-word-masking': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-large-cased-whole-word-masking-pytorch_model.bin", 'bert-large-uncased-whole-word-masking-finetuned-squad': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-large-uncased-whole-word-masking-finetuned-squad-pytorch_model.bin", 'bert-large-cased-whole-word-masking-finetuned-squad': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-large-cased-whole-word-masking-finetuned-squad-pytorch_model.bin", 'bert-base-cased-finetuned-mrpc': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-cased-finetuned-mrpc-pytorch_model.bin", 'bert-base-german-dbmdz-cased': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-german-dbmdz-cased-pytorch_model.bin", 'bert-base-german-dbmdz-uncased': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-german-dbmdz-uncased-pytorch_model.bin", }例:
from pytorch_transformers import BertModel,BertTokenizer,BertConfig model_name = 'bert-base-uncased' model = BertModel.from_pretrained(pretrained_model_name_or_path=model_name) tokenize = BertTokenizer.from_pretrained(pretrained_model_name_or_path=model_name) config = BertConfig.from_pretrained(pretrained_model_name_or_path=model_name)注:也可通过cache_dir参数指定下载的预训练文件的缓存位置,例
from pytorch_transformers import BertModel model_name = 'bert-base-uncased' cache_dir = '/data/usr/bert_cache_dir' model = BertModel.from_pretrained(pretrained_model_name_or_path=model_name, cache_dir=cache_dir) -
(2)当其为预训练文件所在文件夹的名字
则要求预训练文件符合符合命名规范才能被识别。
- model文件: pytorch_model.bin
- vocab文件:vocab.txt
- config文件:config.json
from pytorch_transformers import BertModel,BertTokenizer,BertConfig bert_path = '/data/usr/bert_dir' # 预训练模型的3个文件已经下载到该目录、并按要求命名。 model = BertModel.from_pretrained(pretrained_model_name_or_path=bert_path) tokenize = BertTokenizer.from_pretrained(pretrained_model_name_or_path=bert_path) config = BertConfig.from_pretrained(pretrained_model_name_or_path=bert_path) -
(3)当其为预训练文件的路径
直接对应3种预训练文件的真实路径即可,例
from pytorch_transformers import BertModel,BertTokenizer,BertConfig model_path = '/data/usr/bert_dir/bert-base-uncased-pytorch_model.bin' vocab_path = '/data/usr/bert_dir/bert-base-uncased-vocab.txt' config_path = '/data/usr/bert_dir/bert-base-uncased-config.json' model = BertModel.from_pretrained(pretrained_model_name_or_path=model_path) tokenize = BertTokenizer.from_pretrained(pretrained_model_name_or_path=vocab_path) config = BertConfig.from_pretrained(pretrained_model_name_or_path=config_path)
-
4. Bert模型加载和使用
(1)transformers已经提供了一些基线任务的Bert调用代码,当然你也可以自定义模型:
(2)以文本分类为例,自定义模型BertForTextClassification调用Bert预训练模型:
-
自定义的网络需要继承BertPreTrainedModel类,并将BertMode添加到网络中
from transformers import BertModel, BertPreTrainedModel class BertForTextClassification(BertPreTrainedModel): def __init__(self, config, args): super(BertForTextClassification, self).__init__(config) self.num_labels = config.num_labels self.preoutput_dim = args.hidden_size self.bert = BertModel(config) self.dropout = nn.Dropout(config.hidden_dropout_prob) self.linear = nn.Sequential( nn.Linear(config.hidden_size, self.preoutput_dim), nn.ReLU(), ) self.classifier = nn.Sequential( nn.LayerNorm(self.preoutput_dim * 2), nn.Linear(self.preoutput_dim * 2, self.preoutput_dim), nn.ReLU(), nn.Linear(self.preoutput_dim, self.num_labels), ) self.init_weights() def forward(self, title_ids, content_ids_1, content_ids_2, labels=None): title_output = self.bert(title_ids)[1] title_output = self.dropout(title_output) title_output = self.linear(title_output) content_output_1 = self.bert(content_ids_1)[1] content_output_1 = self.dropout(content_output_1) content_output_1 = self.linear(content_output_1) x = torch.cat([title_output, content_output_1], -1) logits = self.classifier(x) outputs = logits if labels is not None: if self.num_labels == 1: # We are doing regression loss_fct = MSELoss() loss = loss_fct(logits.view(-1), labels.view(-1)) else: loss_fct = CrossEntropyLoss() loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1)) outputs = loss return outputs -
实例化网络,并加载预训练的权重
tokenizer = BertTokenizer.from_pretrained(args.model_name_or_path) # 实例化BertTokenizer,并加载vocab文件 config = BertConfig.from_pretrained(args.model_name_or_path, num_labels=3) # 例化BertConfig,并加载config文件。分类类别数num_labels此时传入,会连同bert超参数保存到config中 model = BertForTextClassification.from_pretrained(args.model_name_or_path, args, config=config) # 实例化自定义网络BertForTextClassificatio、并加载预训练模型参数(model文件)。config为上一步得到的config对象,args为下游任务额外用到的超参数,可以以此方式传递给自定义的网络。BertForTextClassification虽然是自定义的,但是它继承了BertPreTrainedModel,可以直接用from_pretrained方法加载模型的权重(model文件)。
